前文分析了 NameNode,本文进一步解析 DataNode 的设计和实现要点。
文件存储
DataNode 正如其名是负责存储文件数据的节点。HDFS 中文件的存储方式是将文件按块(block)切分,默认一个 block 64MB(该大小可配置)。若文件大小超过一个 block 的容量可能会被切分为多个 block,并存储在不同的 DataNode 上。若文件大小小于一个 block 的容量,则文件只有一个 block,实际占用的存储空间为文件大小容量加上一点额外的校验数据。也可以这么说一个文件至少由一个或多个 block 组成,而一个 block 仅属于一个文件。
block 是一个逻辑概念对象,由 DataNode 基于本地文件系统来实现。每个 block 在本地文件系统中由两个文件组成,第一个文件包含文件数据本身,第二个文件则记录 block 的元信息(metadata)如:数据校验和(checksum)。所以每一个 block 对象实际物理对应两个文件,但 DataNode 不会将文件创建在同一个目录下。因为本机文件系统可能不能高效的支持单目录下的大量文件,DataNode 会使用启发式方法决定单个目录下存放多少文件合适并在适当时候创建子目录。
文件数据存储的可靠性依赖多副本保障,对于单一 DataNode 节点而言只需保证自己存储的 block 是完整且无损坏的。DataNode 会主动周期性的运行一个 block 扫描器(scanner)通过比对 checksum 来检查 block 是否损坏。另外还有一种被动的检查方式,就是当读取时检查。
文件操作
HDFS 支持的文件操作包括写入(新增、追加)、读取和删除。HDFS 定义了一种 multi-reader, single-writer 的文件访问语义。而访问标准依然参照大家熟悉的依据 POSIX(Portable Operating System Interface)为单机文件系统定义的 API。
- Open 打开文件
- Read/Write 读写文件
- Close 关闭文件
下面我们分别讲述文件操作的设计实现要点。
写文件
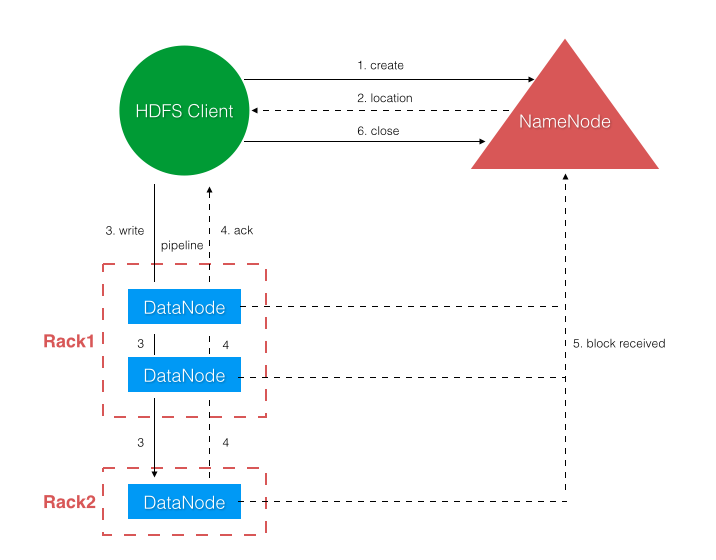
写文件流程如图示,在分布式环境下,Client 请求 NameNode 获得一个针对指定文件的租约(lease,本质上是一种分布式锁,详细请自行维基百科下)。只有持有该租约的 Client 可以向该文件写入,以这种机制来确保写文件的 single-writer 的语义。获得写入租约后 NameNode 向 Client 分配一组用于存放文件数据的 DataNodes,若配置的副本数为 3,则会返回 3 个 DataNode。这一组 DataNodes 被组成一条流水线来写入,有效提升写入性能降低写入延迟。Client 将文件组织成一个个 packet 发送给流水线上第一个 DataNode,第一个 DataNode 存储下该 packet 后再转发给第二个 DataNode,依此类推。然后 DataNodes 再按流水线反方向发回确认 packet 给 Client。当所有文件 block 写入完成后,DataNodes 会向 NameNode 报告文件的 block 接收完毕,NameNode 相应去改变文件元数据的状态。
写文件的主体流程如上所述,如果过程中一切正常那么多么简单美好。但实际在分布式环境下,写文件过程涉及 Client、NameNode 和一组 DataNodes,这其中任何一个环节都有可能产生异常。按照分布式设计第一原则:Design for failure,我们需要考这个流程中的所有参与者都有可能出现失败异常的情况。这里先提出这个问题,考虑每种失败异常的场景下,软件设计实现要怎么去处理?本文先不在这里展开论述,后面会专门撰文深入分析。
读文件
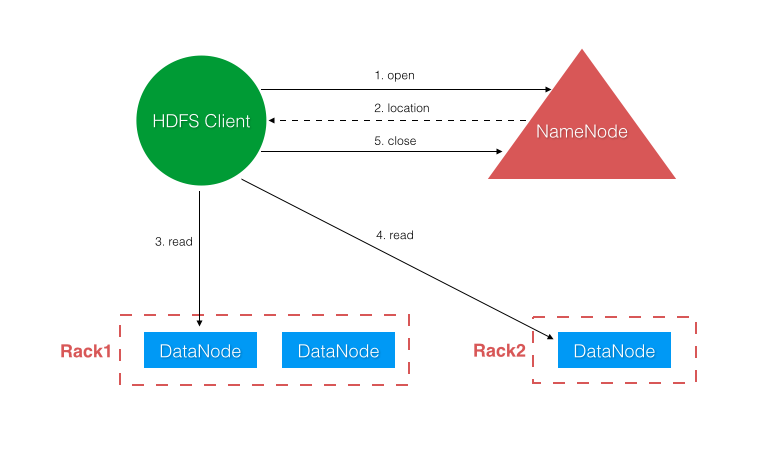
读文件流程如图示,Client 首先请求 NameNode 定位文件 block 所在的 DataNodes。然后按顺序请求对应的 DataNodes 读取其上存储的 block。关于读取顺序,HDFS 有一个就近读取的优化策略,DataNodes 的读取排序会按照它们离 Client 的距离来确定。距离的概念主要区分以下几种场景:
- 距离 0,表示在同一个节点上
- 距离 2,表示同一个机架下的不同节点
- 距离 4,表示同一个数据中心的不同机架下
- 距离 8,表示不同的数据中心
删文件
文件删除的处理首先将文件重命名后放进 /trash 目录。文件会在 /trash 目录中存放一段时间(可配置),在时间到期后再自动清理。所以实际上文件删除操作非常轻量级,仅仅是 NameNode 的内存数据结构的变动,真正的物理删除在后续的自动清理时才做。
可见性
在文件写入过程中,HDFS 不保证文件对其他 Client Reader 可见。只有文件的 block 已经写入 DataNode,并报告给了 NameNode 更新到正确的状态才对其他 Reader 可见。简单说,如果一个文件有多个 block,写入总是发生在最后一个 block 上,那么前面的 block 对其他 Reader 是可见的,但最后一个 block 则不可见,这涉及 block 的状态变化,这里先不展开,后面会专门撰文深入分析。
生命周期
DataNode 启动后首先连接到 NameNode 完成握手,握手的目的是验证 DataNode 的软件版本和 namespace ID。namespace ID 是整个 HDFS 集群的唯一标识,如果 DataNode namespace ID 或 软件版本与 NameNode 不匹配,DataNode 将无法加入集群并自动关闭。若是一个全新的 DataNode 启动时没有 namespace ID,则在握手时由 NameNode 分配并加入集群。此外,NameNode 还会分配一个集群全局唯一的 storage ID 给 DataNode 用于唯一标记,之后不再改变。
完成握手后,DataNode 会立刻向 NameNode 发送 block report 信息,block report 就是 DataNode 上存储了哪些文件 block 的列表。之后会定期(默认 1 小时)向 NameNode 报告。此外,DataNode 将定时向 NameNode 发送心跳(默认 3 秒)来报告自身的存活性。一段时间(默认 10 分钟)收不到 DataNode 最近的心跳,NameNode 会认定其死亡,并不会再将 I/O 请求转发到其上。心跳除了用于 DataNode 报告其存活性,NameNode 也通过心跳回复来捎带控制命令要求 DataNode 执行,因为 NameNode 设计上不直接调用 DataNode 其控制命令都是通过心跳回复来执行,所以心跳的默认间隔比较短。
除了 DataNode 的非正常死亡外,DataNode 还可以正常退休,可以通过管理端标记一个 DataNode 进入退休中(decommissioning)状态。处于退休中状态的 DataNode 不再服务于写请求(包括从 Client 写入或从其他 DataNode 复制),但它可以继续服务读请求。进入退休中状态的 DataNode 将被安排将其上存储的所有 block 复制到其他节点,完成这个过程后 NameNode 将其标记为已退休(decommissioned)状态,然后就可以安全下线了。
总结
本文重点描述了,DataNode 生命周期对 HDFS 集群整体的影响以及文件访问操作的流程。对于异常处理部分没有详细展开讲述,这个系列的后续文章还会进一步深入剖析。
参考
[1] Hadoop Documentation. .
[2] Robert Chansler, Hairong Kuang, Sanjay Radia, Konstantin Shvachko, and Suresh Srinivas. [3] Tom White. . O’Reilly Media(2012-05), pp 94-96下面是我自己开的一个微信公众号 [瞬息之间],除了写技术的文章、还有产品的、行业和人生的思考,希望能和更多走在这条路上同行者交流,有兴趣可关注一下,谢谢。

版权声明:本文为博主原创文章,未经博主允许不得转载。